
IDIP
Ignitec is a Cloud & Database Platform Integrator providing DBaaS, Cloud & Data Cost optimization, and customized advanced analytics solutions. Ignitec’s IDIP (Ignitec Data Intelligence Platform) solutions provides a fully autonomous, 100% open-source, columnar data store with no lock in and delivers high velocity, real-time analytics for data intelligence.
The Problem: You're spending too much on your Data Stack. Here are the possible reasons
- Bloated RDBMS: RDBMS is meant to ensure WRITE/UPDATE transactions integrity, consistency and reliability at small scales of data (few 100 GBs to ~100TB). Beyond this, RDBMS (invented in 1986 with Postgres) doesn’t scale, it slows down and gets expensive since the infra becomes too large to manage
- RDBMS used for analytics: Row-based stores are excellent for ACID WRITEs. They are unoptimised for analytical reads of any kind. So if you’re using your MySQL, MSSQL, or Postgres for OLAP querying, you’re likely seeing super expensive and super slow queries
- Legacy “Big Data” OLAP solutions: With Hadoop, Vertica, Infobright, Greenplum, etc. you’re likely struggling with legacy architectures (e.g., MapReduce), expensive licensing, resource-intensive dataops, and complex & cumbersome ecosystem. All this leads to high cost of software, storage and compute infrastructure
- Cloud Data Warehouses: The likes of Snowflake, BigQuery, Redshift, etc. operate some of the most predatory pricing schemes in world of software, with 20-40x compute markups, strong vendor & data lock-in with closed-source proprietary software in the cloud, bundled ecosystem where you pay as much for the integrations (data pipes, observability) as you do for the CDW, and usage based billing where your bills compound 30-100% year on year. Further, they work well for batch analytics but get slow & expensive for real-time analytics
Our
Clientele









What's the way out? The Solution
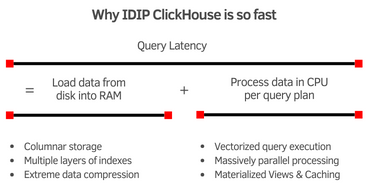
- Resource-efficient DBMS: IDIP ClickHouse is the world’s fastest and most efficient real time analytics DBMS.
- Columnar store, with excellent data compression => lowest storage costs
- Data compression + multiple layers of indexes + column pruning => lowest cost of disk IO to load data to RAM
- Vectorized query execution + massively parallel processing => lowest cost of query execution
- Materialized views, caching, 10+ use case specific storage engines, nuanced GROUPBY, JOIN implementations => resource efficient frequent & complex query execution
- Right-Sizing:
- World’s most resource-efficient analytics DBMS => can do in 50 or less servers what incumbents might take for 100 or more, due to columnar nature, data compression, layers of indexes, MPP, vectorized execution, multiple specialized storage engines, etc. Ignitec teams also work with customers to right-size their infrastructure
- Right-sizes RDBMS by using IDIP ClickHouse technology
- Rightsizes cost of peripherals with an 100% open source ecosystem of bundled tools
- Open source software: with zero vendor lock-in – the code is public, do with it as you please
- Take software to your data: so you don’t incur the costs associated with data gravity and can make the most of your existing data infrastructure, wherever it already is: cloud, on-prem, VPC. Single OLAP vendor across all modes of deployment, so you incur none of the costs of multiple vendors
- Bundled ecosystem: so all the paraphernalia (data pipes, AI/ML integrations, BI, observability) comes 100% free and open source along with the OLAP software
- Predictable infrastructure: Centrally provisioned and set in stone with data platforms team for all enterprise workloads. You don’t have a tsunami of democratically provisioned warehouses running bad SQL that keeps compounding your bills, as you would with Snowflake
- Fixed price billing: Flat-price 24*7 enterprise class SLA-based support. Always the fixed price, no questions asked. For managed services, pay a flat price per node, control your bill.
Technology
Partners



ll these things make the IDIP solution an economical alternative compared to CDW and legacy big data OLAP. Now add to this our IDIP Proxy solution for Data Fabric:
- IDIP ClickHouse for analytics: When old data, typically used for analytics, is written to IDIP ClickHouse from RDBMS, RDBMS can be used for ACID WRITEs alone. All analytical reads can be split to IDIP ClickHouse, reducing any spend associated with RDBMS for analytics
- RDBMS archival store: With read-write splitting, IDIP ClickHouse can be used to store old data in RDBMS, compressing it by 5-10x over RDBMS. RDBMS becomes much leaner, and much cheaper, saving both infra and RDBMS software cost
Ignitec is a Cloud & Database Platform Integrator providing DBaaS, Cloud & Data Cost optimization, and customized advanced analytics solutions. Ignitec’s IDIP (Ignitec Data Intelligence Platform) is powered by ChistaDATA ClickHouse & Data Fabric to provide a fully autonomous, 100% open-source, columnar data store with no lock in and delivers high velocity, real-time analytics as well an orchestration layer that integrates into your current state data stack for high performance and secure data intelligence.
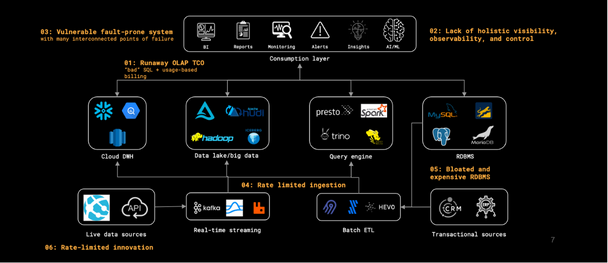
Enterprise data platform sprawl has created problems
- Growing propensity for “bad” (resource-intensive) SQL in conjunction with the usage-based billing models of closed-source, proprietary and unbundled ecosystem platforms has created analytics bills that compound year-over-year.
- Heterogeneous database systems exist in effective siloes. They may provide control planes, cost control mechanisms and observability dashboards independently, but there is no single plane of control & visibility for the data stack as a whole.
- Tens of components implies hundreds of interconnections and, effectively, hundreds of potential points of failure. System resilience and fault-tolerance is that much harder to achieve & maintain, and cyber-attack surface area is large & growing.
- Rate-limited ingestion – As data volumes grow exponentially with rise of machine data (time-series machine/sensor data, logs, clickstream & web events), high-velocity data ingestion and real-time data streaming is the need of the hour. No incumbents can solve this.
- RDBMS aren’t built for today’s scale. As data size grows into 10s / 100s of TBs, performance suffers and costs grow due to RDBMS bloat. Horizontally scaling and partitioning your RDBMS will only take you so far.
- With so many moving parts and interdependencies, innovation particularly at the highly-sensitive database layer is throttled given the fear of tampering with and bringing down a highly complex and unpredictable system.
Why you’re paying runaway analytics bills
- Usage-based billing for CDWs – All CDWs bill on usage, i.e., compute per minute & often, IOPS. A single bad SQL query implies hundreds if not thousands of dollars wasted.
- Massive compute markups – Markups to the tune of 10-50x the base cost of compute are very common across the leading cloud data warehouse and lakehouse vendors.
- Unbundled ecosystem with point solutions – For every $100 on Snowflake you’re probably spending $50-100 across ecosystem tooling by independent vendors such as ETL data pipes, data catalogs, data quality.
- “Throwing the kitchen sink” to scale legacy architecture – To speed up slow queries in legacy architectures, these solutions throw resources (more clusters, more shards) at the problem, compounding your bills.
Key Functions and Integration Capabilities of Data Fabric
- DATA Fabric is a reverse proxy server positioned atop various database systems, serving effectively as a “database gateway”.
- It channels all database queries and their responses to destinations such as BI applications and ML models.
- The Fabric creates a control, visibility, and orchestration layer over the database layer, integrating isolated data segments into a continuous “fabric”, and merging formerly separate elements into a single, communicative entity.
- It is equipped with capabilities that allow it to appropriately route individual queries, intercept, examine and alter queries, and compile query logs to ensure full system visibility and observability.
- Read-write splitting – Load balances & routes requests to the appropriate nodes in your stack
- Blacklist & optimize SQL – Configure the proxy with rules to prevent unwanted SQL executions
- Consumption visibility – Log aggregation (internal & external) to know resource consumption by query
- Multi-DB protocol aware – Supports ClickHouse, MySQL, PostgreSQL, and a growing number of DB protocols
- Highly secure – HTTP endpoint with HTTPS / TCP-TLS exchange with forwarding SSL support.
- Forever GPL + extensible arch – 100% GPL-licensed fabric software + plugin-based extensible architecture.
Data Fabric creates a leaner & faster data stack
- OLAP TCO optimization – Leverages ClickHouse as an effective “cache” for expensive and frequent query patterns, splitting reads away from incumbent into ClickHouse, to execute at fraction of cost. Also, Fabric blacklists resource-intensive SQL before it hits the DB layer.
- Unified control plane for observability & visibility – Fabric aggregates all DBMS query logs and provides a metrics agent to monitor performance & cost across all databases in the stack in one pane of glass, both at a per-query level and at a holistic system level.
- Secure & resilient, fault-tolerant systems – Proxy server acts as secure HTTP endpoint with encrypted communications to & from the database layer, with blacklisting to prevent execution of malicious SQL, as well as load balancing, RTO & service state discovery for high-availability.
- High-velocity real-time data ingestion – Leverages a unique build of ClickHouse known as ClickRocks that integrates with RocksDB, a persistent key-value store to achieve high WRITE amplification. System can now ingest 100s of billions of rows per day in ClickHouse.
- Leaner & performant RDBMS – Archives historical data from RDBMS into ClickHouse with extreme compaction, and splits analytical reads away from RDBMS into ClickHouse, creating a much leaner, faster and cost-optimized RDBMS used only for transactional WRITEs.
- Zero-disruption integration & innovation – Simply integrate a set of lightweight Asabru proxy servers above your database to get started with Fabric, and customize them to your needs. No need for any complex data migration, Fabric optimizes cost & performance without modifying the stack.